Overview
When running a query, the system will return a row of data for every combination of return values that you specify. Consequently, for data elements that can exist multiple times in a person's record (like phone numbers, contact management records, contributions, etc...), the query engine will return one row for each combination of those multiple row columns returned.
For example, let's say your query returns PID, First Name, Last Name and Contacted Date like this: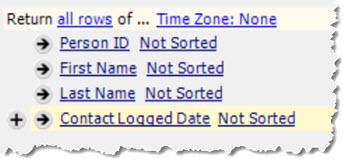
If someone has two contact records in their profile, you will get the following result:
1012 John Smith 5/1/2018
1012 John Smith 5/5/2018
The Solution
There are two simple strategies for working with data like this to force it to a single row per record.
- Using Exclude Duplicate Rows
- Using Aggregation
Using Exclude Duplicate Rows
Sometimes you may get multiple lines per record even when you do not explicitly select columns to be returned that have different values. This can be caused because the underlying record data in the schema you have chosen is focused on the multiple rows of data as it's primary context.
For example, if you selected First Name and Last Name as your return values when running a query using the "Contributions, Contributors & Financials" schema, you would get each donor's First Name and Last Name repeated per row for each gift that the donor has made. This is because that schema has a context focused on the contributions so it will report back your selected data for each contribution that meets your criteria.
To cope with those situations, the top area of the query "return Set" field list has the option to return "All Rows" or "Exclude Duplicate Rows".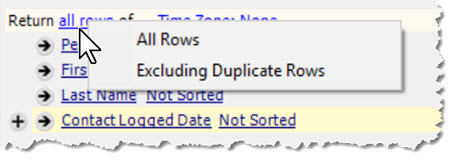
Using Aggregation
Let's say you just wanted to get the most recent contact date, thereby only one date would be returned, hence, only one row would be returned by the query. This approach is called "Aggregation" - where you take the underlying data and aggregate it to present a particular element of that data.
You may add an aggregation to any returned value by choosing it from the action icon (->) in the return fields list:
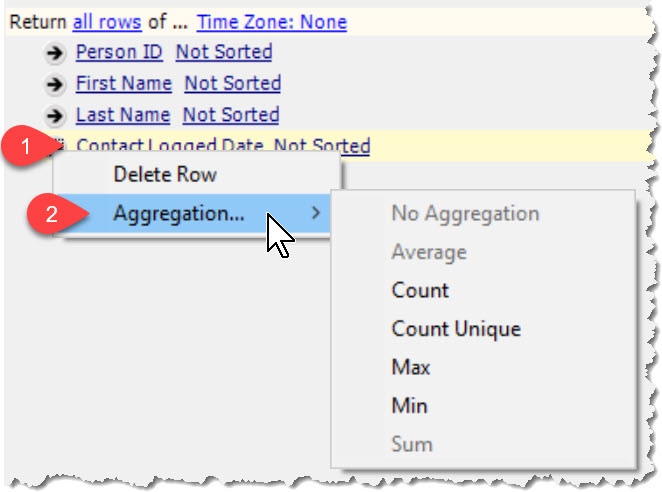
Your options for aggregation are:
| Aggregation Type | What It Does |
|---|---|
| Count | Returns the number of records - ie: "2" would be returned for our example above |
| Count Unique | Returns the number of unique records, eliminating any duplicates in the list |
| Min | Returns the minimum sorted value (or in the case of dates, the oldest date) |
| Max | Returns the maximum sorted value (or in the case of dates, the most recent date) |
| Average | If a numeric value, returns the average number - eg: the average donation side of all donations received. |
| Sum | If a numeric value, this returns the total sum of all items in the list. |
When you choose aggregation for a return field, the query type changes to "Grouped Rows" and it makes the aggregation options also available in the query filter area.
![]()
This is useful where you may wish to filter based on criteria such as "Count of Contact Event Dates is greater than 1" to return only those persons that have more than one contact event.
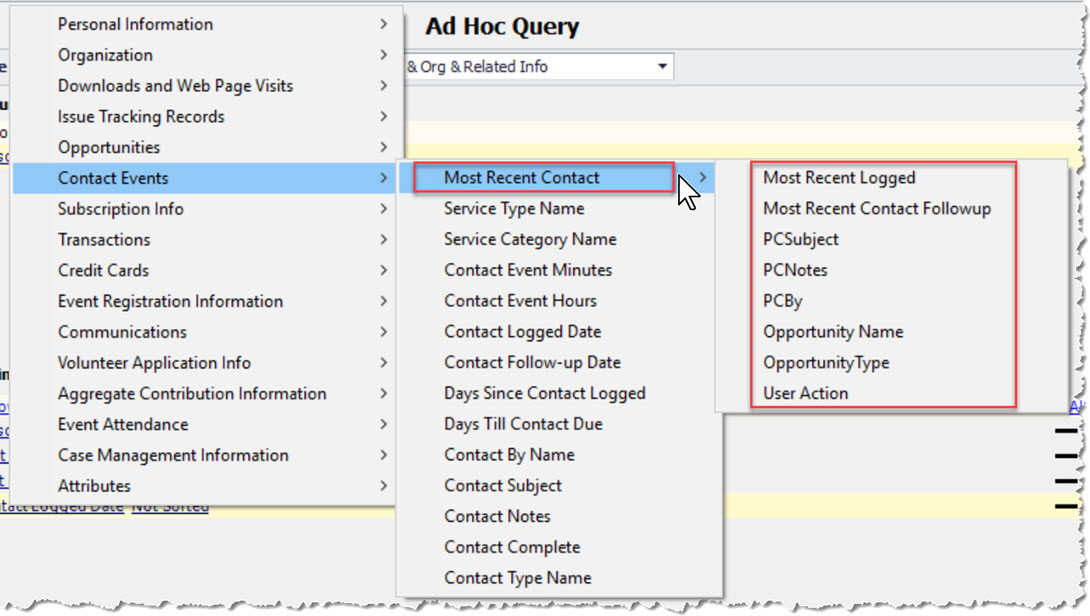
NOTE: Many schemas have pre-defined aggregates already in the field list for you. In the case of the most recent contact event used in the above example, there is a section that contains "Most Recent" values for the latest contact event.
Summary
You may choose Aggregate Grouping" or "Exclude Duplicates" for any given query, but both cannot be used at the same time. Changing the query type to "Exclude Duplicates will remove any aggregates that you have defined in the query.
Comments
0 comments
Please sign in to leave a comment.